みなさん、こんにちは。
先日、リアル(対面)会議の議事録作成を「ICレコーダー+NotebookLM」を使って極限まで効率化する記事を書きました。
生成される議事録の品質には大満足だったので、「よし、次はこの取り込み作業の完全自動化だ!」と意気込んで取り組んでいたのですが……実際に運用してみると、いくつか思わぬ課題にぶつかってしまいました。
- NotebookLMへのアップロード容量が「1ファイルあたり200MBまで」という制限がある
- 連続した複数の会議データを、会議ごとに分割したいときがある
- 実は、あとから録音データそのものを「耳で聞き返す場面」がそれなりにある
容量制限については、自動化の途中で圧縮をかければ解決します。しかし、それ以外の2つが「完全全自動化」への大きな壁になりました。
まずデータの分割について。複数の会議が立て続けに行われた場合、会議ごとに録音データを切り分けたいときがありますよね。これを全自動でそのままアップロードしてしまうと、NotebookLM側で要約させるときに内容がごちゃ混ぜになってしまいます。そこで、完全自動化は一歩手前で止め、「いったん音声データを手動で目的の場所で分割してから、NotebookLMへアップロードする」というステップを挟むことにしました。
そして、一番の想定外だったのが「録音データを後から聞き返す場面が結構あった」ということです。「あのとき、なんて言ってたっけ?」「現場のニュアンスをもう一度確認したい」と思うことが意外とあるんですよね。
そのときに猛烈に気になったのが、ICレコーダー特有の「ザー……」という不快なホワイトノイズ。AIにテキスト化してもらうだけならノイズがあっても問題ないのですが、人間の耳で聞き返すとなると、これがもう不快極まりないわけです。
そこで、自動化のターゲットを、音声ファイルの自動アップロードではなく、「ホワイトノイズを綺麗に消し去り、200MB以内にバッチリ圧縮された超軽量なMP3データを一括で作成すること」に変更することにしました!
今回はLinuxユーザーの方向けに、「SoX」と「FFmpeg」を組み合わせ、フォルダ内の全WAVファイルからコマンド一発でノイズを消し去り、さらに軽量なMP3へと一括自動変換するシェルスクリプトをご紹介します。
事前準備 – 必要なツールのインストール
今回の処理には、音響操作の万能ナイフである SoX と、動画・音声変換の超定番 FFmpeg を使用します。 UbuntuやDebianなどの主要なLinuxディストリビューションであれば、おなじみのAPTコマンドで一発インストールできます。
sudo apt update
sudo apt install sox ffmpeg
下準備 – 「何がノイズか」をAIならぬSoXに学習させる
SoXのノイズ除去アルゴリズムは、「何がノイズ(不要な環境音)なのか」を事前に学習させておく必要があります。
やり方は簡単。ICレコーダーの録音データの最初や最後にある、「誰も喋っていない(環境音だけがザーと鳴っている)3〜5秒ほどの無音区間」を、Audacityなどの音声編集ソフトで切り出します。 そして、それを noise_sample.wav といった名前で保存しておいてください。
お使いのICレコーダーによってノイズの特性は決まっているので、この作業は最初の1回だけでOKです!
コマンド一発!一括処理シェルスクリプト
それでは、以下のコードを clean_and_convert.sh という名前で保存してください。
#!/bin/bash
# 引数のチェック(対象フォルダとノイズ用WAVのパスが必要)
if [ -z "$1" ] || [ -z "$2" ]; then
echo "【エラー】引数が足りません。"
echo "使用例: ./clean_and_convert.sh /path/to/folder /path/to/noise.wav"
exit 1
fi
TARGET_DIR="$1"
NOISE_WAV="$2"
TEMP_PROF=$(mktemp /tmp/noise_prof.XXXXXX)
TEMP_WAV=$(mktemp /tmp/temp_cleaned.XXXXXX.wav)
# 1. SoXでノイズプロファイル(学習データ)を作成
echo "[1/3] ノイズプロファイルを作成中..."
sox "$NOISE_WAV" -n noiseprof "$TEMP_PROF"
if [ $? -ne 0 ]; then
echo "【エラー】ノイズプロファイルの作成に失敗しました。"
exit 1
fi
# 2. フォルダ内のWAVファイルをループ処理
echo "[2/3] フォルダ内の一括処理を開始します: $TARGET_DIR"
cd "$TARGET_DIR" || exit 1
# 大文字小文字を区別せず .wav にマッチさせる
shopt -s nocaseglob
for file in *.wav; do
# ファイルが存在しない場合の保護
[ -e "$file" ] || continue
# 絶対パスを取得し、ノイズ用WAV自体を二重処理しないようスキップ
abs_file=$(realpath "$file")
abs_noise=$(realpath "$NOISE_WAV")
if [ "$abs_file" = "$abs_noise" ]; then
continue
fi
echo "--------------------------------------------------"
echo "処理中: $file"
# 拡張子を除いたファイル名を取得
filename="${file%.*}"
# SoXでノイズ除去(一時ファイルへ出力)
sox "$file" "$TEMP_WAV" noisered "$TEMP_PROF" 0.21
# FFmpegでMP3に変換(ボイス録音に最適な40kbps指定)
ffmpeg -y -i "$TEMP_WAV" -codec:a libmp3lame -b:a 40k "${filename}.mp3"
done
# 3. 一時ファイルのクリーンアップ
rm -f "$TEMP_PROF" "$TEMP_WAV"
echo "--------------------------------------------------"
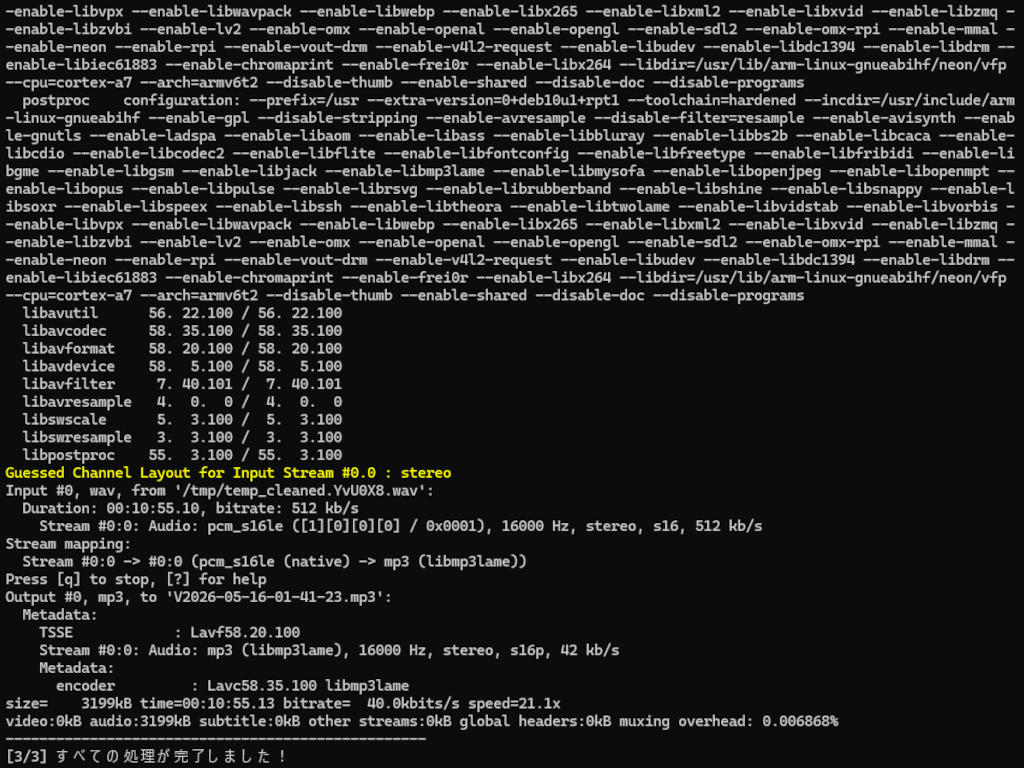
echo "[3/3] すべての処理が完了しました!"
保存したら、ターミナルで実行権限を与えておきましょう。
chmod +x clean_and_convert.sh
使い方(本当にコマンド一発です)
ターミナルを開き、「スクリプトのパス」「音声ファイルが詰まったフォルダのパス」「先ほど用意したノイズ用WAVのパス」をスペース区切りで指定して実行するだけ!
./clean_and_convert.sh "/home/user/Music/IC_Recorder_Data" "/home/user/Music/noise_sample.wav"
これを実行すると、指定したフォルダ内のすべてのWAVファイルが綺麗にノイズ除去され、同じフォルダ内に同名の .mp3 ファイルが次々と生成されていきます。
こだわり派のためのチューニングのヒント
録音環境や好みに応じて、スクリプト内の数値を少し書き換えるだけで、音質やファイル容量を自由に微調整できます。
1. ノイズを削る「強さ」を変えたい
スクリプト内の noisered "$TEMP_PROF" 0.21 にある 0.21 という数値を変更します。
0.20〜0.25あたりが、声の輪郭を崩さずにノイズだけを消し去るベストバランスです。- この数値を大きくしすぎると、ノイズは消えますが、肝心の声がシュワシュワしたデジタル特有の変な音(いわゆる宇宙人マイク状態)になってしまうので注意してください。
2. ビットレート(容量と音質のバランス)を変えたい
今回はICレコーダーの「声(会話)」を想定しているため、容量を極限まで削れる 40k(40kbps) に設定しています。これはいわば「AMラジオ」相当の音質ですが、人の声を聞き取る分には全く問題なく、ファイル容量を劇的に小さく(数百MBのWAVが数十MBに!)できます。
- もし「音楽演奏の録音だからもっと高音質で残したい」という場合は、
192kや320kに変更してください。 - 逆に「とにかくテキスト化できればいいからもっと容量を削りたい」という場合は、
32kや24kまで落とすことも可能です。
ラズベリーパイで実行するなら5を推奨
Linuxの強力なCUIツールである SoX と FFmpeg を組み合わせれば、重いGUIアプリをいちいち開くこともなく、大量の録音データを一瞬でクリアな軽量MP3に仕立て上げることができます。
ちなみにこのスクリプト、もちろん省電力なラズベリーパイ(Raspberry Pi)でも動作します。ただ、手元にあったRaspberry Pi 3B+で走らせてみたところ、流石に音声処理が重く処理速度に不満が残りました……(笑)。もしラズパイで運用するなら、パワフルな Raspberry Pi 5 あたりで実行するのが良さそうです。
「ICレコーダーの会議データ、あとから結構聞き返すんだよね」という方や、「NotebookLMのアップロード容量制限をスマートにクリアしたい」というLinuxユーザーの方は、ぜひお試しください!
本日も最後までお読みいただきありがとうございました。
それでは、よいリアル会議ライフを!